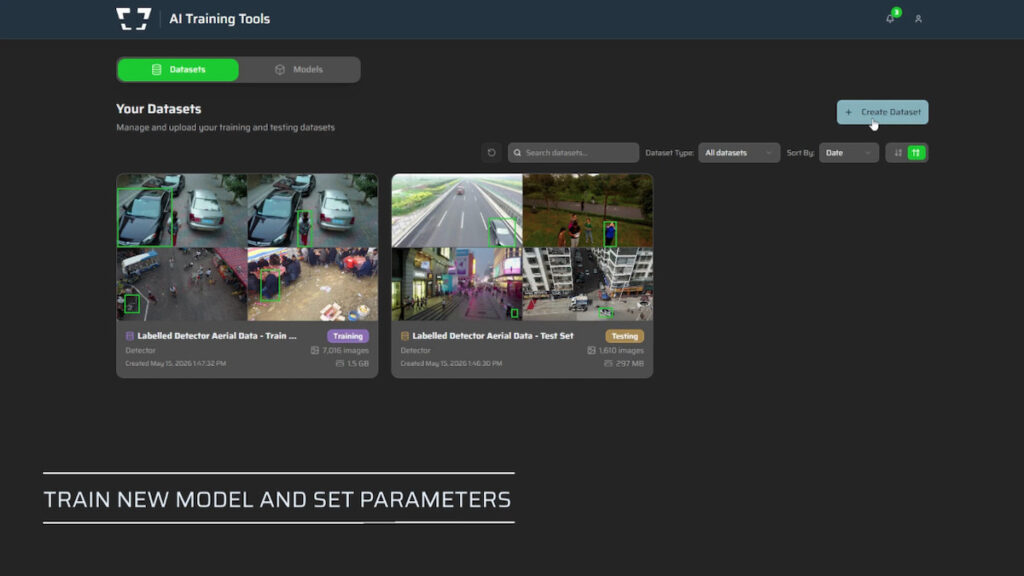
Sightline Intelligence outlines key considerations for interpreting artificial intelligence outputs in Part 2 of ‘Machine Learning for the Warfighter’, focusing on how commonly presented metrics can be misunderstood.
Confidence scores, often assumed to represent probabilities, instead indicate relative certainty based on learned patterns. A higher score reflects a stronger relative ranking and is likely more reliable than lower-confidence detections, but it does not mean the result is correct a corresponding percentage of the time, particularly if the model is not well calibrated.
Standard evaluation metrics such as precision, recall, and Mean Average Precision (mAP) provide structured ways to assess detection performance. Precision measures the proportion of correct detections, while recall reflects how many actual targets are identified. mAP evaluates average precision using overlap thresholds, such as [email protected], which requires at least 50% overlap (IoU) between predicted and actual object locations. These metrics quantify performance but depend heavily on how they are applied and interpreted.
mAP has limitations that affect its reliability in certain scenarios. Small objects are more sensitive to positional shifts, as IoU thresholds penalize them disproportionately, and the metric evaluates detections on a single-frame basis. Operational systems often extend beyond this, incorporating multi-frame tracking to improve effective recall and temporal filtering to reduce false positives, which are not captured in raw model metrics.
Read Part 1 of ‘Machine Learning for the Warfighter’ here >>
Detection systems must balance false positives and false negatives, as reducing one typically increases the other. Lower detection thresholds increase sensitivity but raise false alarm rates, while higher thresholds reduce false positives at the risk of missed detections. The appropriate balance varies depending on operational requirements and system objectives.
Constraints associated with edge AI deployments further influence performance. Running AI systems on constrained hardware with limited compute, memory, and power requires trade-offs in model size, resolution, and architecture, which can affect robustness.
When models operate at the limits of their computational budget, understanding their limitations and failure modes becomes critical. Performance metrics are only meaningful when tied to relevant data, making it essential to evaluate systems using test sets that reflect actual operating conditions rather than relying solely on vendor-reported results.
In Part 3, Sightline Intelligence will explore how thoughtful system architecture can mitigate these challenges and build more reliable edge AI systems.
To find out more information, read ‘Part 2: Machine Learning for the Warfighter’ here >>