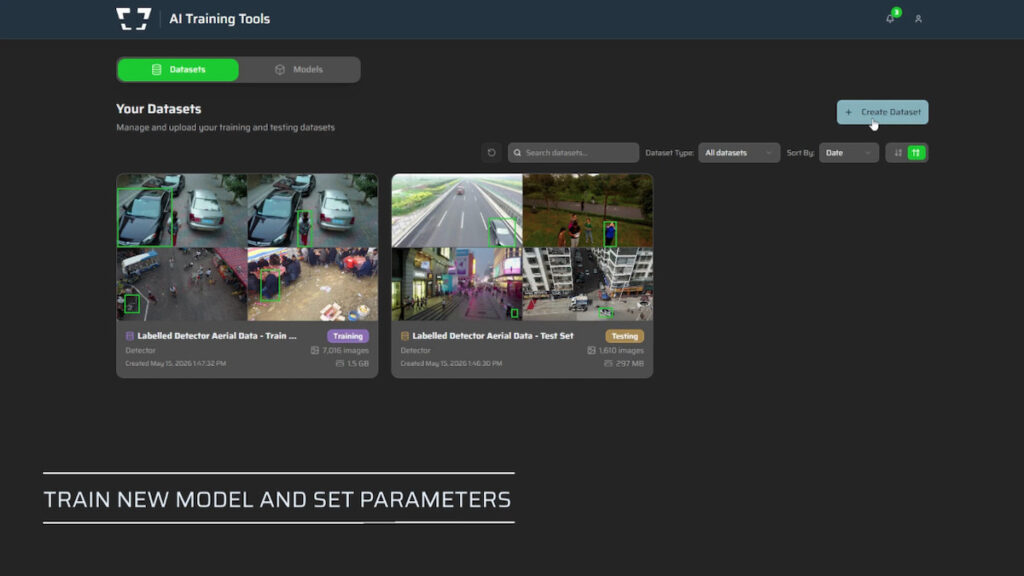
Sightline Intelligence examines how artificial intelligence, particularly computer vision models used for detection and classification, differs from traditional rule-based software and why data fundamentally defines system performance in Part 1 of ‘Machine Learning for the Warfighter’.
Traditional software operates using explicit, pre-defined instructions that produce consistent outcomes regardless of where or how the system is deployed. Artificial intelligence systems do not function in this way. Instead of following fixed rules, machine learning models learn patterns from large volumes of labeled data.
For example, a model trained on thousands of images of vehicles in desert terrain will perform well in that environment, but this capability is directly tied to the data it has seen. Performance is therefore limited by the diversity and quality of both training and test datasets, as models cannot reliably interpret conditions that fall outside of those examples.
This dependency extends beyond simple geographic variation. Differences in sensor type, such as electro-optical versus long-wave infrared, introduce fundamentally different visual characteristics. Environmental factors including dust, maritime conditions, vegetation, and urban glass reflections further alter how objects appear.
Lighting and weather also play a significant role, with models often struggling in low-light or adverse conditions if such scenarios were not adequately represented during training. In addition, changes in operational perspective, such as ground-based versus aerial viewpoints, create entirely different visual patterns that must be learned.
Generalization & Performance in Operational Environments
The challenge of generalization has been well documented. Research has shown that even minor variations, such as changes in image compression, camera systems, or lighting, can lead to substantial reductions in accuracy. Models that perform strongly in controlled testing environments can experience notable degradation when exposed to slightly different conditions.
In defense scenarios, this can manifest when systems trained in one operational theater encounter new environments with different weather, sensor inputs, and background complexity, resulting in performance outside previously validated conditions.
Test datasets provide a measure of confidence by defining the scenarios in which performance has been evaluated, but they cannot account for every possible situation. Rare or complex combinations of factors are difficult to capture comprehensively, and operational environments continue to evolve as new terrains, sensor technologies, and adversary behaviors emerge.
These realities do not limit the usefulness of AI systems, but they require a structured approach to deployment. This includes understanding operational boundaries, monitoring performance over time, and planning for iterative retraining as new data becomes available.
Part 2 will examine specific failure modes and performance metrics, and outline the importance of independently curated test data in evaluating system performance.
To find out more information, read ‘Part 1: Machine Learning for the Warfighter’ here >>